
Current state-of-the-art spatial reasoning-enhanced VLMs are trained to excel at spatial visual question answering (VQA). However, we believe that higher-level 3D-aware tasks, such as articulating dynamic scene changes and motion planning, require a fundamental and explicit 3D understanding beyond current spatial VQA datasets. In this work, we present SpatialPIN, a framework designed to enhance the spatial reasoning capabilities of VLMs through prompting and interacting with priors from multiple 3D foundation models in a zero-shot, training-free manner. Extensive experiments demonstrate that our spatial reasoning-imbued VLM performs well on various forms of spatial VQA and can extend to help in various downstream robotics tasks such as pick and stack and trajectory planning.
Motivation: Many works enhance VLMs' spatial reasoning by training/fine-tuning them on standard spatial VQA datasets, leading to surface-level associations between image-text-data triplets. Given the scarcity of spatially rich embodied data and high-quality 3D annotations, we hypothesize that VLMs may struggle to generalize beyond their dataset or adapt to more complex spatial tasks.
Key Insight: Recent studies in image space understanding show that VLMs, with internet-scale language knowledge and multimodal foundation models, capture complementary information that enables new tasks across modalities without further training. With advances in 3D foundation models, we explore using 3D priors to enhance VLMs' higher-level spatial awareness.
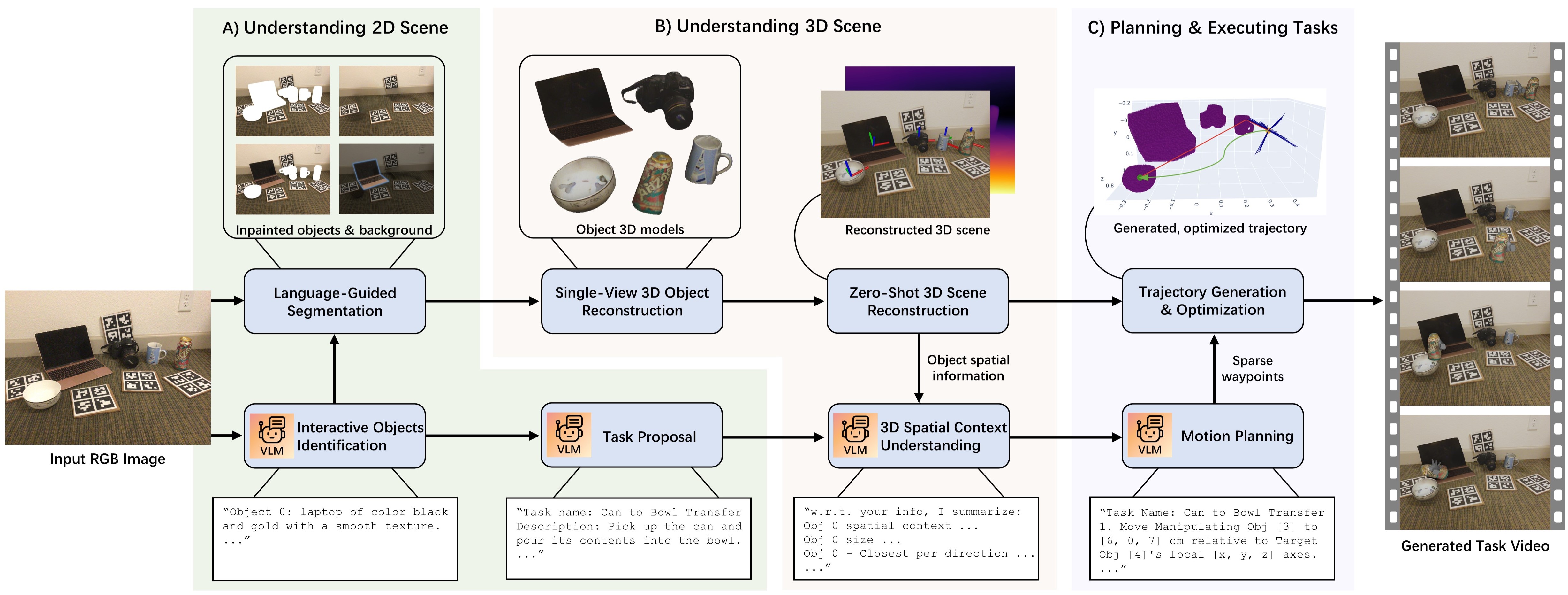
Approach: Our modular pipeline enhances VLMs' spatial understanding of an image through progressive prompting and interactions with 2D/3D foundation models as "free lunch", with scene decomposition, comprehension, and reconstruction processes.
We provide an extensive empirical study combining multiple off-the-shelf and handcrafted datasets, ranging from fundamental spatial questions regarding relative positions and orientations to providing fine-grained 3D information on objects' locations, sizes, inclinations, and dynamic changes, and plan for robotics tasks with full 3D trajectories.
We experiment on the basic form of spatial VQA introduced by SpatialVLM, Intra-Image Object Relations VQA (IaOR-VQA),
as well as two new forms introduced by us: Intra-Image Angular Discrepancies VQA (IaAD-VQA) and Inter-Image Spatial Dynamics VQA (IrSD-VQA).
In the figure below, we list some sample question and answer pairs generated by our pipeline.

By partially reconstructing the 3D scene with visual alignments, our framework enables VLMs to use tools like rapidly-exploring random tree star (RRT*) to generate accurate, collision-free paths based on task specifications. Given a robot's egocentric observation of a scene with multiple objects, our pipeline uses traditional planning to solve robotics pick-and-stack.

We present a novel task that requires advanced spatial reasoning capacities of VLMs. Given a single RGB image of any scene comprising unknown environments and objects, the VLM discovers potential tasks and plans their execution with full 3D trajectories, with the motivation that it can be used for robot learning in future research. To solve this complex task and visualize the execution using our framework, we introduce: 1) a task proposal approach using VLM, 2) a novel axes-constrained 3D planning approach that enables spatial reasoning-imbued VLM to plan the object motion based on the proposed tasks by specifying waypoints.



















@inproceedings{ma2024spatialpin,
title={SpatialPIN: Enhancing Spatial Reasoning Capabilities of Vision-Language Models through Prompting and Interacting 3D Priors},
author={Ma, Chenyang and Lu, Kai and Cheng, Ta-Ying and Trigoni, Niki and Markham, Andrew},
booktitle={Proceedings of the Conference on Neural Information Processing Systems (NeurIPS)},
year={2024}
}